Безопасность
mysurik
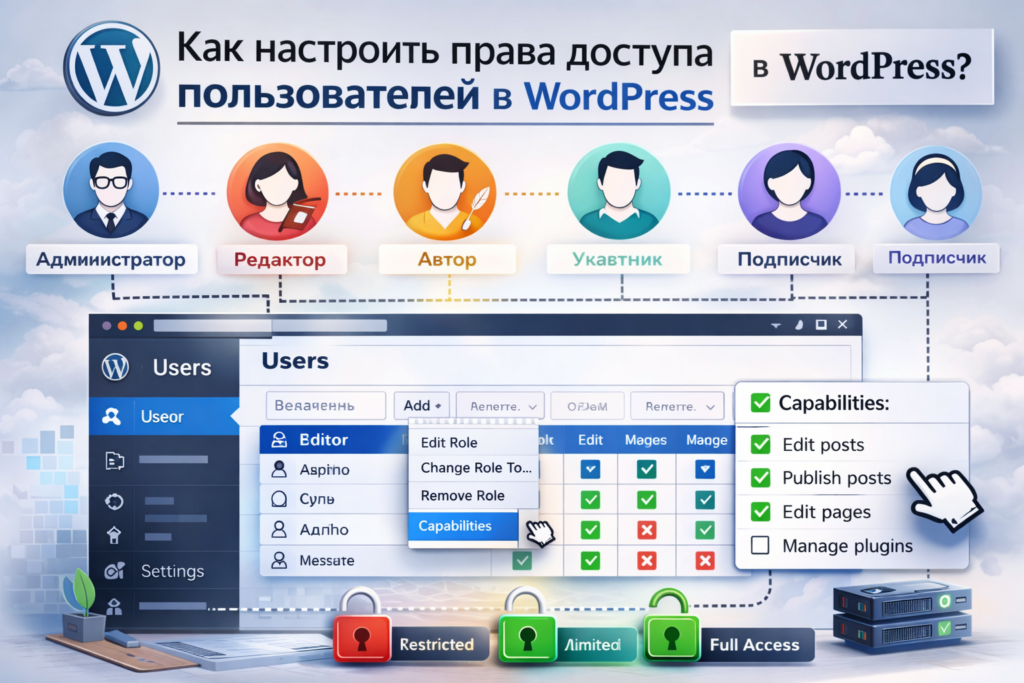
Безопасность WordPress: что я делаю чтобы сайт не взломали
Первый раз меня взломали в 2018 году. Зашёл в админку, а там — белый экран и кривой баннер про «ваш сайт взломан». Хорошо, был свежий бекап. С тех пор я подошёл к безопасности системно и хочу поделиться, что реально работает, а что — маркетинговая ерунда. В админку я захожу только через двухфакторку — без неё […]
ЧИТАТЬ ПОДРОБНЕЕ →